 The “Power-Efficient GPU and heterogeneous Multi-/Many-core Computing” (PEGPUM) workshop has been accepted for inclusion in the HiPEAC event in 2017. The workshop will be held on January 24, 2017 in Stockholm, Sweden, co-located with the HiPEAC conference (https://www.hipeac.net/2017/stockholm/). This will be the 5th PEGPUM workshop, after PEGPUM 2013, PEGPUM 2014, PEGPUM 2015, and PEGPUM 2016. Previous editions of PEGPUM were organized by the LPGPU and LPGPU2 consortia. Next year’s editions will be co-organized with four other European projects targeted at improving the power efficiency of GPUs and heterogeneous multi-/many-core systems: Tulipp, SAFEPOWER, Hercules, and Eyes of Things. Stay tuned for more information!
The “Power-Efficient GPU and heterogeneous Multi-/Many-core Computing” (PEGPUM) workshop has been accepted for inclusion in the HiPEAC event in 2017. The workshop will be held on January 24, 2017 in Stockholm, Sweden, co-located with the HiPEAC conference (https://www.hipeac.net/2017/stockholm/). This will be the 5th PEGPUM workshop, after PEGPUM 2013, PEGPUM 2014, PEGPUM 2015, and PEGPUM 2016. Previous editions of PEGPUM were organized by the LPGPU and LPGPU2 consortia. Next year’s editions will be co-organized with four other European projects targeted at improving the power efficiency of GPUs and heterogeneous multi-/many-core systems: Tulipp, SAFEPOWER, Hercules, and Eyes of Things. Stay tuned for more information!
Author Archives: Jan Lucas
PEGPUM 2017
Posted by Jan Lucas
on July 15, 2016
No comments
f2f meeting in Athens
Posted by Jan Lucas
on July 15, 2016
No comments
The LPGPU2 consortium had a very successful face-to-face meeting in Athens on June 15 and June 16, 2016. The main topic was the design and implementation of the power analysis, visualization, and improvement framework. Present at the meeting were Ben Juurlink and Jan Lucas from TUB, Andrew Richards, Luke Iwanski, Mehdi Goli from Codeplay, Georgios Keramidas, Iakovos Stamoulis, Mixalis Koziotis, and Panagiotis Apostolou from Think Silicon, Graham Mudd, Philip Harmer, and Prashant Sharma from Samsung, and Mauricio Alvarez-Mesa from Spin Digital.
Paper accepted at MASCOTS 2016
Posted by Jan Lucas
on June 20, 2016
Comments Off on Paper accepted at MASCOTS 2016

The paper “ALUPower: Data Dependent Power Consumption in GPUs” by Jan Lucas and Ben Juurlink has been accepted at MASCOTS 2016. It describes in detail how data values influence the power consumption of GPUs and how the power consumption can be modeled.
The MASCOTS conference is a well-established forum for state-of-the-art research on the measurement, modeling, and performance analysis of computer systems and networks. The 24th edition of this conference will take place September 21-23, 2016 in Imperial College Campus, London. The conference will bring together academics and industry practitioners to present and discuss their latest research results. The technical program for the 3-day conference will include keynote talks, refereed full and work-in-progress papers.
More information can be found at: san.ee.ic.ac.uk/mascots2016/
LPGPU2 Project publishes its first press release!
Posted by Jan Lucas
on February 8, 2016
Comments Off on LPGPU2 Project publishes its first press release!
PEGPUM 2016 Workshop Program now online!
Posted by Jan Lucas
on January 5, 2016
Comments Off on PEGPUM 2016 Workshop Program now online!
The Program of the upcoming PEGPUM 2016 workshop is now online. PEGPUM is now organized by the LPGPU2 project. It will feature 6 talks with speakers from the Industry and Universities. We hope to see you soon at HiPEAC 2016 in Prague.
LPGPU is back!
Posted by Jan Lucas
on October 22, 2015
Comments Off on LPGPU is back!
There wil be a LPGPU2 project. Stay tuned for more information!
PEGPUM 2016 Workshop
Posted by Jan Lucas
on October 22, 2015
Comments Off on PEGPUM 2016 Workshop
The PEGPUM Workshop will return to HIPEAC 2016 in Prague. This is the fourth installment of this successful workshop and will feature many interesting talks. It will be the first workshop of the new LPGPU2 project. Please stay tuned for more news and check out the workshop page.
Paper accepted in ACM TACO
Posted by Jan Lucas
on October 22, 2015
Comments Off on Paper accepted in ACM TACO
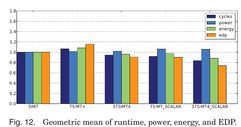
The paper “Spatiotemporal SIMT and Scalarization for Improving GPU Efficiency” by Lucas et al. has been accepted for publication in ACM TACO (http://dl.acm.org/citation.cfm?id=2811402). Because it is original work, it will also be presented at the yearly HiPEAC conference, which is the premier European network event on topics central to ACM TACO and has been attended by more than 600 scientists in 2015. HiPEAC 2016 will be held in Prague (https://www.hipeac.org/2016/prague).
LPGPU Paper in IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
Posted by Jan Lucas
on July 30, 2014
Comments Off on LPGPU Paper in IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
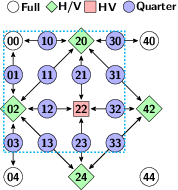
The paper “Parallel H.264/AVC Motion Compensation for GPUs using OpenCL” by Biao Wang, Mauricio Alvarez-Mesa, Chi Ching Chi, and Ben Juurlink has been accepted as a Transactions Letter at IEEE Transactions on Circuits and Systems for Video Technology (TCSVT). It will appear in an upcoming issue of the IEEE Transactions on Circuits and Systems for Video Technology.
Abstract: Motion compensation is one of the most compute-intensive parts in H.264/AVC video decoding. It exposes massive parallelism which can reap the benefit from Graphics Processing Units (GPUs). Control and memory divergence, however, may lead to performance penalties on GPUs. In this paper, we propose two GPU motion compensation kernels, implemented with OpenCL, that mitigate the divergence effect. In addition, the motion compensation kernels have been integrated into a complete and optimized H.264/AVC decoder that supports H.264/AVC high profile. We evaluated our kernels on GPUs with different architectures from AMD, Intel, and Nvidia. Compared to the fastest CPU used in this paper, our kernel achieves 2.0 speedup on a discrete Nvidia GPU at kernel level. However, when the overheads of memory copy and OpenCL runtime are included, no speedup is gained at application level.
Poster at PUMPS 2014
Posted by Jan Lucas
on July 6, 2014
Comments Off on Poster at PUMPS 2014
A poster from TU Berlin named “On the Potential and Shortcomings of Temporal SIMT GPUs” was selected for the PUMPS 2014 poster season. It will be presented at the PUMPS poster seasons by Jan Lucas from TU Berlin.
