The paper “FPGA-Based Prototype of Nexus++ Task Manager”, by Tamer Dallou, Ahmed Elhossini and Ben Juurlink, is accepted to appear at the 6th Workshop on Many-Task Computing on Clouds, Grids, and Supercomputers, which is Co-located with Supercomputing/SC 2013, on November 17th, 2013, Denver, Colorado, USA.
The Nexus++ task manager is designed for task-based programming 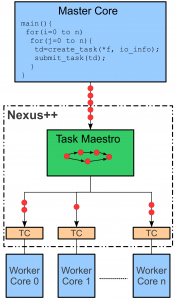 models. Furthermore, it will be ported to GPGPUSim as an extension to add dependency-awareness to GPUs, at block level granularity.
models. Furthermore, it will be ported to GPGPUSim as an extension to add dependency-awareness to GPUs, at block level granularity.
Abstract: StarSs is one of several programming models that try to relieve parallel programming. In StarSs, the programmer has to identify pieces of code that can be executed as tasks, as well as their inputs and outputs. Thereafter, the runtime system (RTS) determines the dependencies between tasks and schedules ready tasks onto worker cores. Previous work has shown, however, that the StarSs RTS may constitute a bottleneck that limits the scalability of the system and proposed a hardware task management system called Nexus++ to eliminate this bottleneck. The first prototype of Nexus++ was implemented in SystemC. Its architecture also had a nondeterministic multi-cycle search algorithm in its critical path, potentially limiting its scalability. In this paper, we improved the architecture of Nexus++ and employed a multi-way set-associative cache-like data structures to optimize its search algorithm and increase task throughput. We also modeled the new architecture in VHDL and targeted a Virtex~5 FPGA from Xilinx. Experimental results show that the new architecture is very resource-efficient utilizing only 19% of the target FPGA. It also shows that Nexus++ achieves a speedup of up to 81x using some synthetic benchmarks modeled after H.264 decoding. Hence, Nexus++ significantly enhances the scalability of applications parallelized using StarSs.
